在商业领域,各个行业、企业或组织都遇到前所未有的全球化、区域化或细分市场多元化的挑战,他们在激烈竞争中对生存和成长的需求推动了对大数据发展的探索和研究。有效地处理、分析和应用这些大数据解决商业问题、助力商业决策,已成为当今各个商业领域的迫切需求。笔者以易于接受的案例阐述、解释和演示商业分析涉及的数据模型(回归、分类、聚类、决策树、关联分析等等),探讨如何用技术和方法去解决实际商业问题。
前一篇文章《数据驱动商业决策之模型魅力(一):线性回归》中,提到线性回归的概念、应用场景,以及机器学习家族的分类。本篇文章则探讨聚类分析,它属于无监督机器学习的一种。
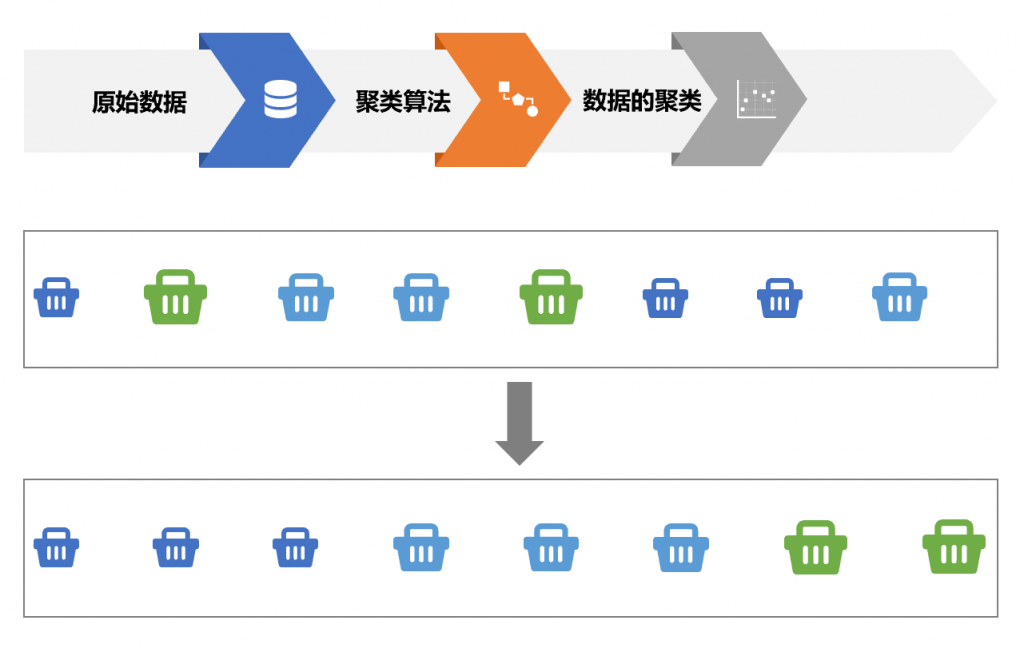
聚类分析是对数据进行处理,识别隐藏的组或者组成不同的区:
聚类的目的是以有益于商业的方式去进行有意义的分析。聚类能够发现以前未检测到的数据集中的关系。例如,市场营销聚类分析可用于市场细分:根据人口统计和交易历史对客户进行细分,从而制定市场营销策略。聚类分析的另一个例子是识别购买类似产品的群体。同样,可以根据生活方式和消费支出对人群进行分组,使用聚类分析预知人群对产品和服务的潜在需求,帮助制定业务和市场营销策略。
最常用的两种聚类方法是层次聚类和划分聚类。在层次聚类中,每一个观测值自成一类,这些类每次两两合并,直到所有的类被聚成一类为止。在划分聚类中,首先指定类的个数K,然后观测值被随机分成K类,再重新形成聚合的类。因为后者能处理大量级数据且容易理解,所以本文介绍基于K均值算法的划分聚类方法。
关注微信公众号,获取最新文章及下载资料
最常见的划分方法是K均值聚类分析。从概念上讲,K均值算法如下:
(1)选择K个中心点(随机选择K行);
(2)把每个数据点分配到离它最近的中心点;
(3)重新计算每类中的点到该类中心点距离的平均值(也就说,得到长度为p的均值向量,这里的P是变量的个数);
(4)分配每个数据到它最近的中心点;
(5)重复步骤(3)和步骤(4)直到所有的观测值不再分配或是达到最大的迭代次数(比如软件设定的迭代次数)。
为方便说明问题,选择以下示例数据作为实验对象,该数据是某公司下属子公司的费用率,为进行绩效考核,需要将其分成三个聚类:
(1)初始时,随机分成三个数据集,每个数据集的第一个数据作为其均值;
(2)将每个数据与三个数据集的均值进行比较,利用欧几里得距离(差的绝对值)作为参考依据,并将其指派进最近的数据集,形成新的数据集;
(3)重复计算每个组的均值;
(4)重复(2)、(3),直至均值不再发生变化。
聚类分析算法相对简单,用Excel VBA语言就能实现,当然涉及到多维度、大量级数据的聚类分析,则需要使用R语言、Python,在后续篇章会深入介绍。
——欢迎预约我们,现场沟通交流。
-300x300.png)

