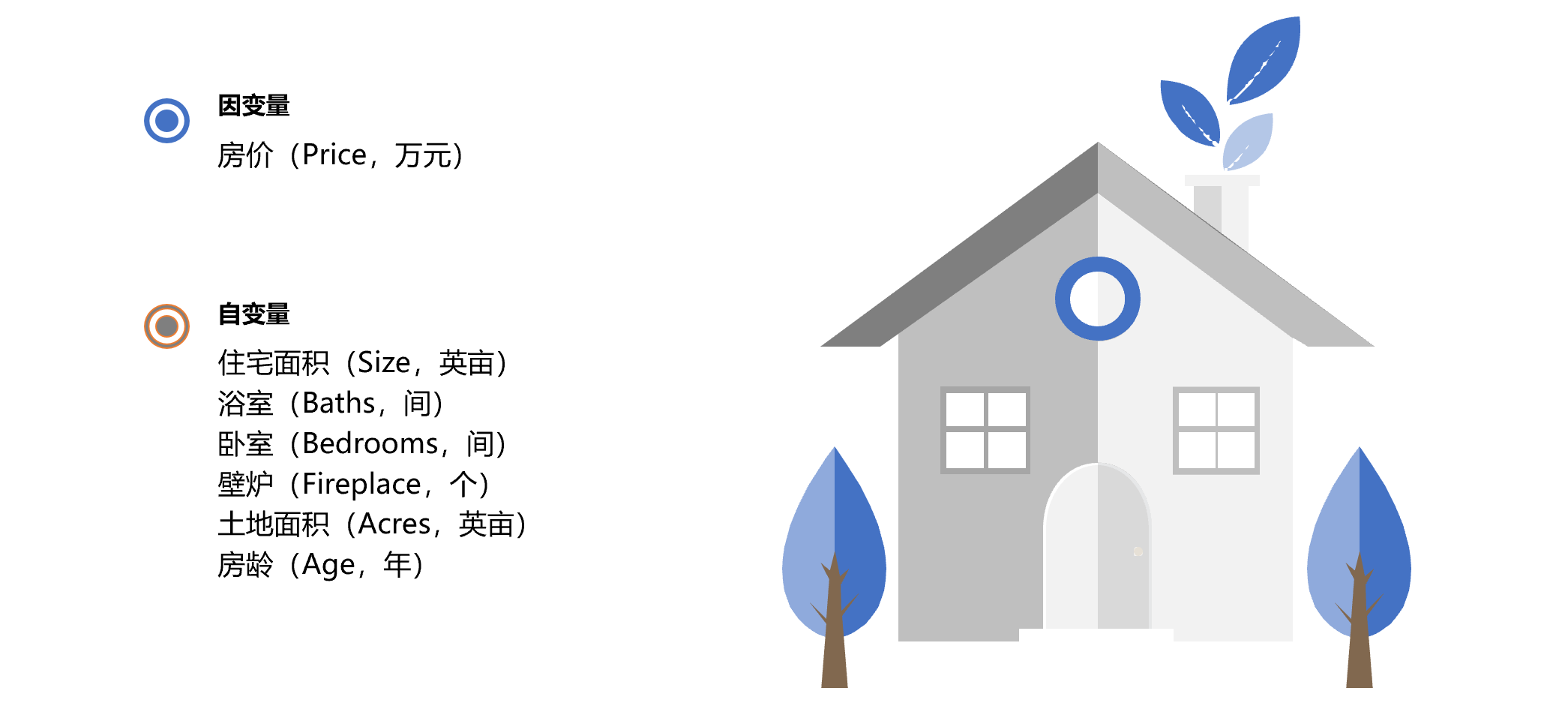
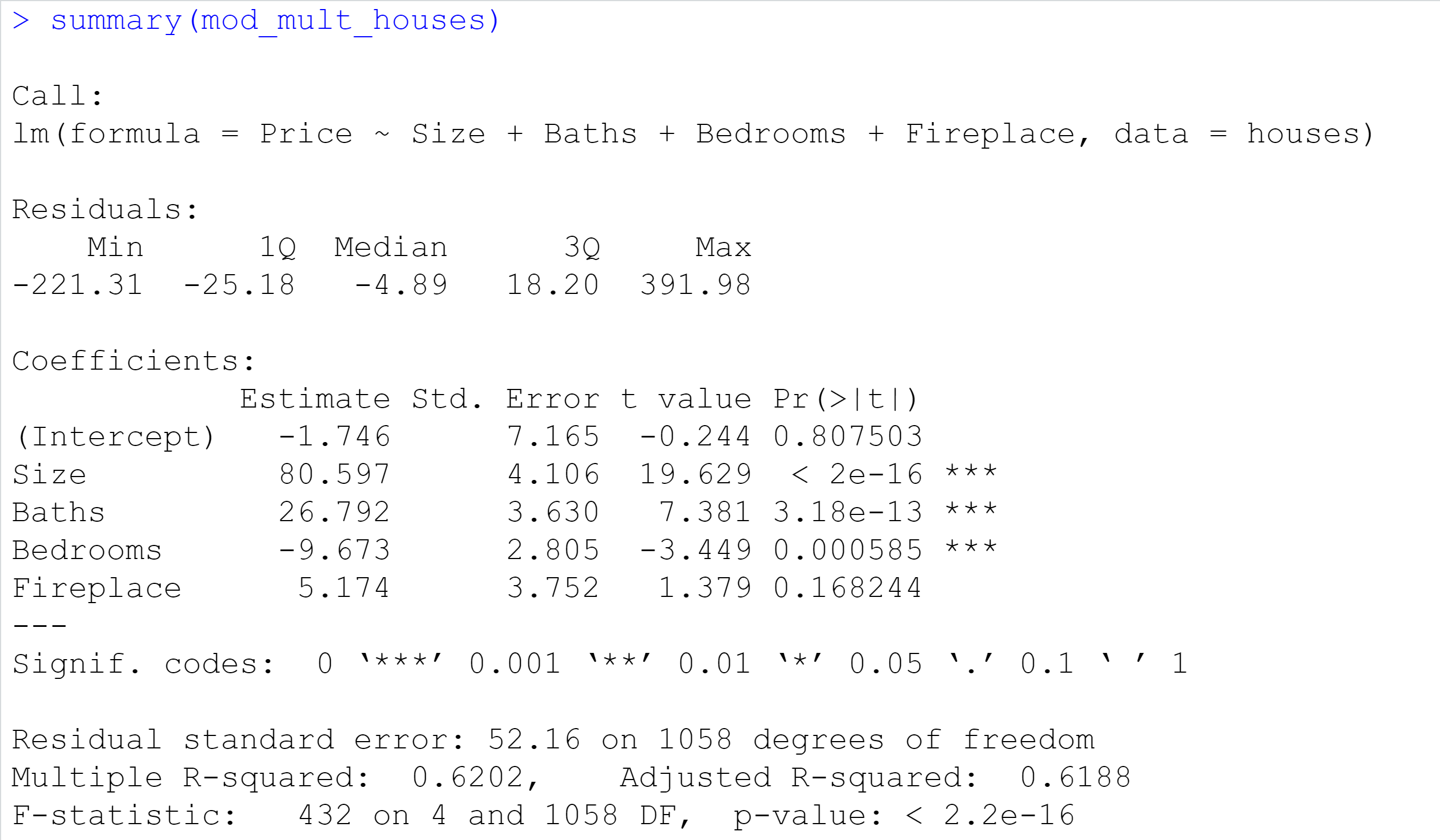
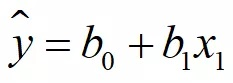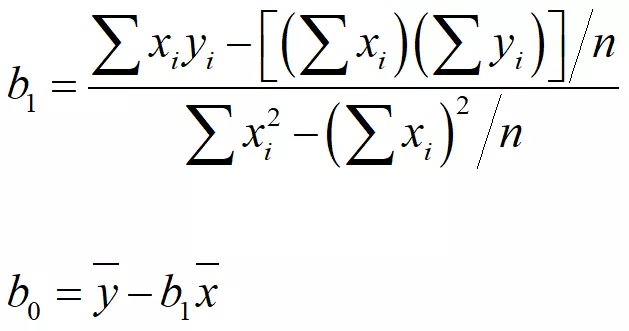本文用RStudio对该数据进行线性回归分析。RStudio是一款R语言的IDE,R自带的环境操作起来可能不是方便,而Rstudio很好地解决了这个问题,而且它还具有调试、可视化等功能,支持纯R脚本。RStudio可以在官网上下载试用,安装也非常方便,限于篇幅就不再赘述。
(1)导入数据
> houses<-read.table(“D:/houses.csv”,header = TRUE,sep = “,”)
- houses是定义的变量,在R语言中称之为数据框;
- <-read.table(“D:/houses.csv”,header = TRUE,sep = “,”),是导入数据文件(同时导入单元格标题),并赋值给houses;
- 可以通过> View(houses)查看数据。
(2)简单线性回归
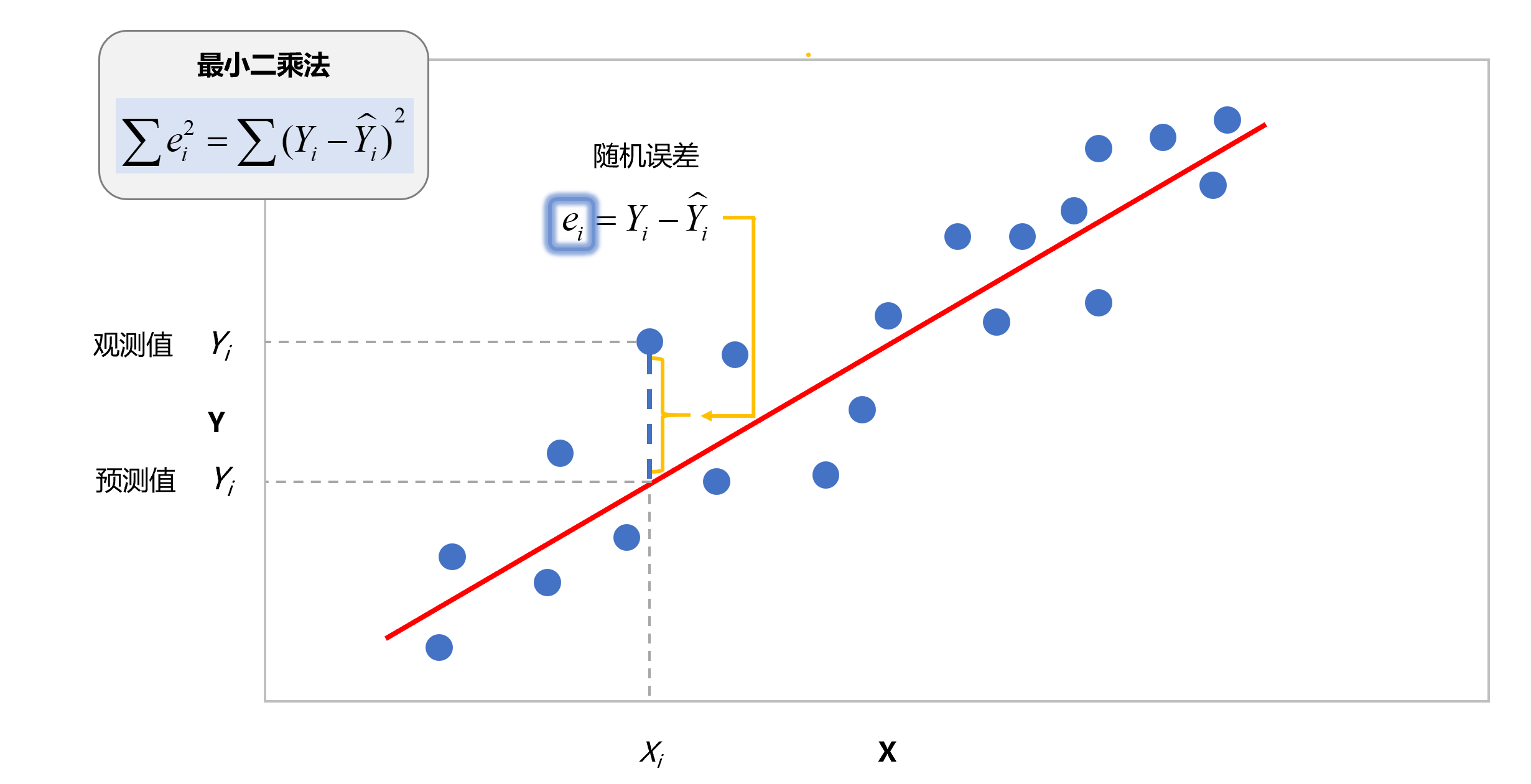
构建房价(因变量)和住宅面积(自变量)之间的简单线性模型,代码如下:
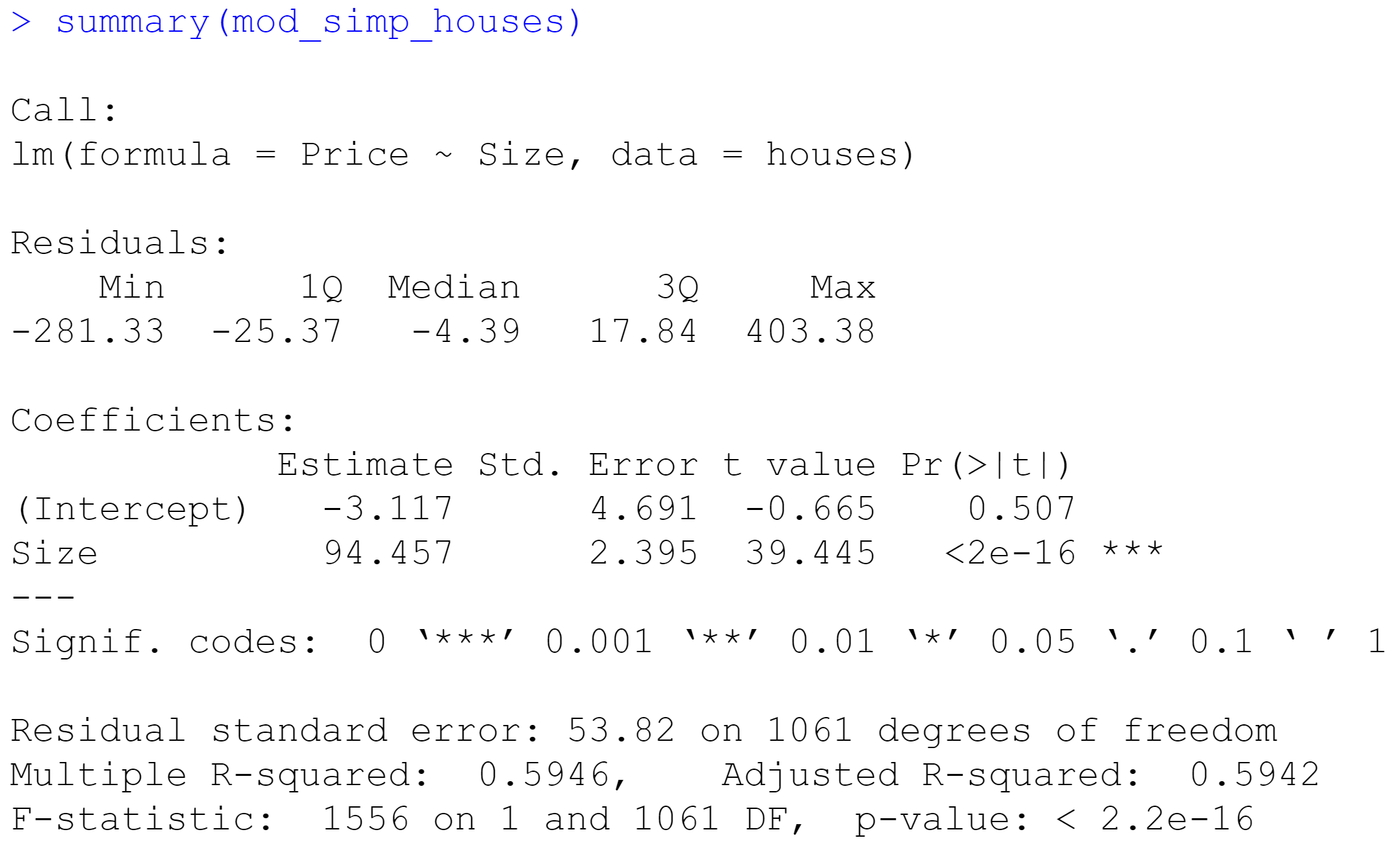
> mod_simp_houses<-lm(Price~Size,data=houses)
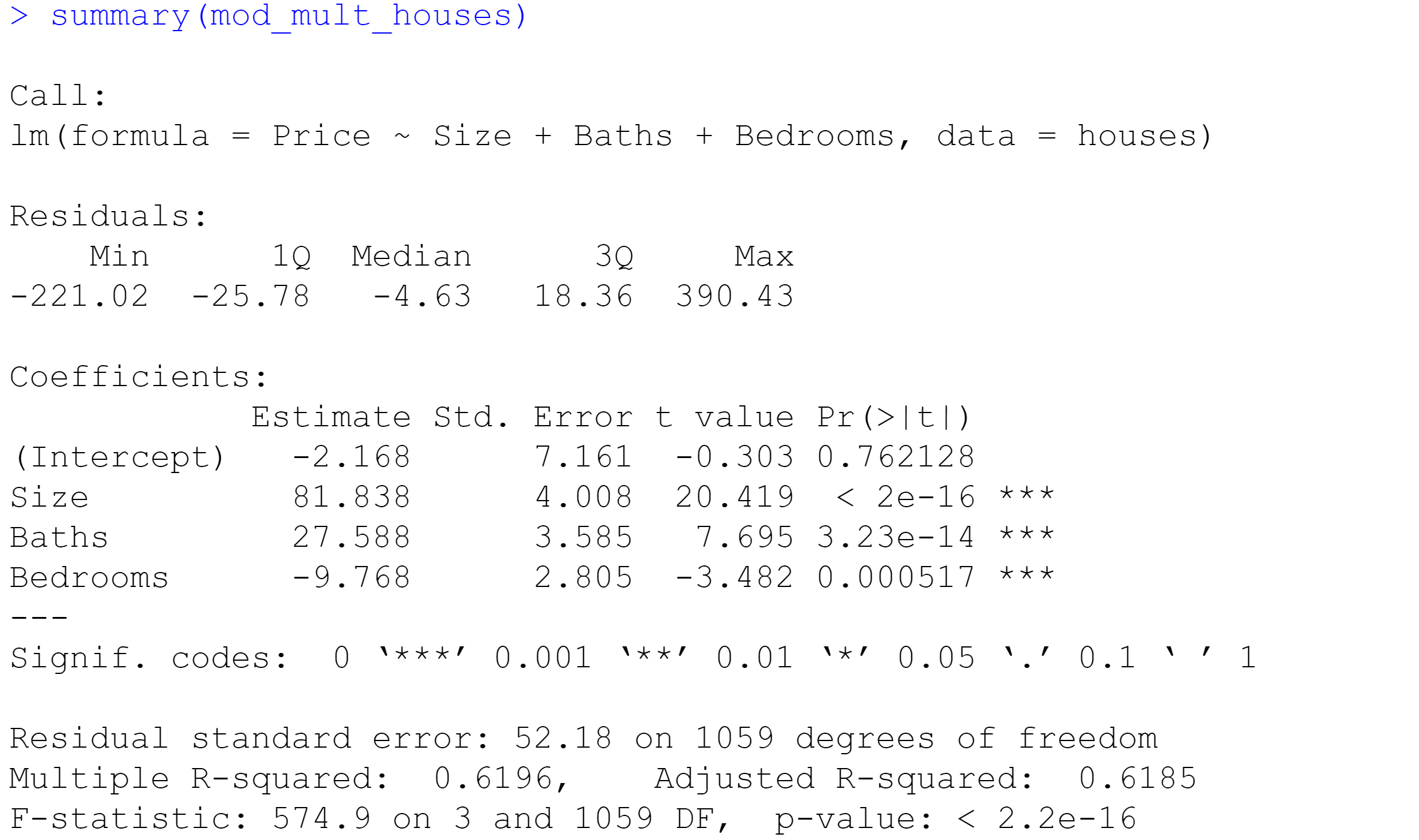
> summary(mod_simp_houses)
- lim(因变量 ~ 自变量,数据=数据框名)是建立线性关系的命令;
- 可以通过> summary(mod_simp_houses),查看线性模型的计算结果。
-300x300.png)